CloudSQLのMySQLインスタンスをレガシー高可用性構成から新しい高可用性構成にアップグレードする
はじめに
私のサービスではデータベースにMySQLを使用しており、CloudSQLで運用しています。CloudSQLには障害時に素早く復旧するために高可用性構成という機能を提供しています。現在はレガシー高可用性構成という古い構成で運用していますが、2021第1四半期からレガシー構成が使用できなくなるようなので、新しい高可用性構成に移行してみようと思います。また、私のサービスではインフラのリソース管理にTerraformを利用しています。そのため、一連の作業はTerraformで行います。
レガシー構成から新しい高可用性構成へ移行する
移行手順はドキュメントに記載してあります。今回はそれに則って移行作業を行います。
- フェイルオーバー レプリカの削除
- 新しい高可用性を使用するように変更
- フェイルオーバー機能のテスト
フェイルオーバーレプリカの削除
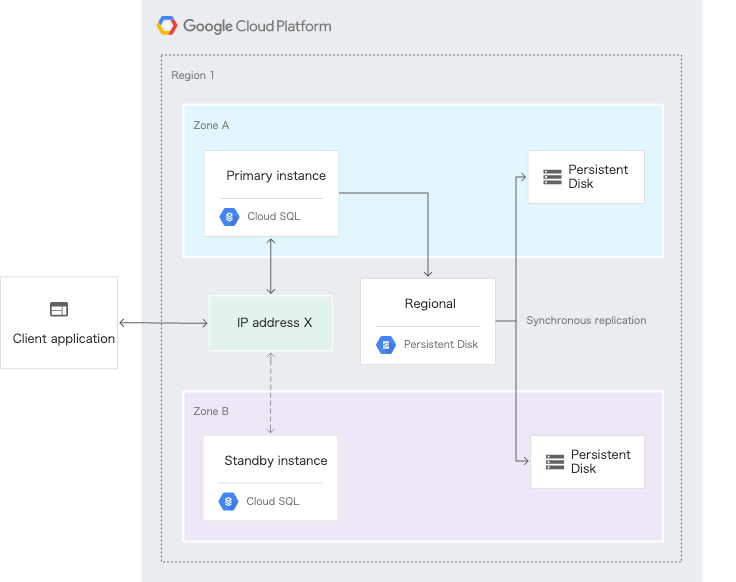
レガシー構成ではフェイルオーバーレプリカインスタンスを使用して高可用性を実現していました。新しい構成ではスタンバイインスタンスと呼ばれる、フェイルオーバーレプリカインスタンスとは別のインスタンスを利用します(下図参照)。そのため、新しい構成に移行する前に、レガシー構成で使用されていたフェイルオーバーレプリカインスタンスをTerraformで削除します。
Terraformでインスタンスを削除するときは、リソース定義を消す前に deletion_protection という削除防止フラグを無効にしておく必要があります。これをしないと、リソース定義を削除しても terraform apply で実行が失敗します。deletion_protection 無効後、リソース定義を削除すると正常にフェイルオーバーインスタンスが削除されます。
resource "google_sql_database_instance" "failover_instance" { name = "failover_instance" region = "asia-northeast1" project = "test-project" database_version = "MYSQL_5_7" deletion_protection = false ... }
新しい高可用性の有効化
Terraformで新しい高可用性を有効化する場合、プライマリインスタンスの availability_type をREGIONALに変更します。これで、 terraform apply を実行すると新しい高可用性への移行が完了します。しかし、高可用性の移行中にダウンタイム(インスタンスの停止時間)が発生してしまいます。そのため、移行の前に影響範囲の調査と被害最小化の対策を考えておく必要があります。私のサービスではデータベースメンテナンス時間を設定し、その時間内に移行作業を行いました。
settings { availability_type = "REGIONAL" }
フェイルオーバー機能のテスト
高可用性が有効にしたので、実際にフェイルオーバーされるかどうかをテストしておきましょう。フェイルオーバーのテスト方法もドキュメントに記載されています。今回は gcloud で行います。準備としてアカウントとプロジェクトを今回使用する値に変更しておきます。
$ gcloud config set project test-project Updated property [core/project]. $ gcloud config set account test@gmail.com Updated property [core/account]. $ gcloud config configurations list NAME IS_ACTIVE ACCOUNT PROJECT default True test@gmail.com sample-project
次に、以下のコマンドでプライマリインスタンスをフェイルオーバーさせます。
$ gcloud sql instances failover test-instance Failover will be initiated. Existing connections to the master instance will break and no new connection can be established during the failover. Do you want to continue (Y/n)? Failing over Cloud SQL instance...done.
フェイルオーバーが完了するとGCPのインスタンスページに以下のようなログが表示されているはずです。

まとめ
今回はCloudSQLの高可用性構成移行について紹介しました。GCPはドキュメントが豊富でわかりやすく、移行作業でハマることはありませんでした(Terraformの削除防止フラグで少し調査したくらい 😅)。利用しているCloudSQLインスタンスでレガシー構成を使用している方がいればぜひ新しい高可用性構成にアップグレードしてみてください 😄
ノイジーアラートを減らすために、DatadogのSmoothing機能でグラフをなめらかにする
はじめに
私のチームではマイクロサービスの監視にDatadogを使っています。先日、ある機能をiOSユーザー向けにリリースしたことでサービスへの負荷が増加し、レイテンシーよくスパイクするようになりました。その結果、モニタリングの結果をポストするチャンネルがノイジーなアラートで溢れかえっています 😢。スパイクの原因はDB周り、ポッドのリソース調整などがあります。しかし、今は年末年始休業ということで大きな変更を伴うリリースができません。そのため、その場しのぎとして、Datadogモニターの設定を変更してノイジーな値を減らそうというわけです。 普段からDatadogを業務で触っていますが、細かい設定をいじったことはありません。今回の記事ではダッシュボード機能の Smoothing(平滑化) という関数を使用して、ノイジーなメトリクスをきれいにしていきたいと思います。
※この記事ではダッシュボード作成については取り扱いません 🙇🏻♂️
Smoothing機能を試す
https://docs.datadoghq.com/dashboards/functions/smoothing/
Autosmooth
これはその名の通り自動で時系列グラフをなめらかにしてくれます(便利😮)。グラフデータ間の移動平均を適切な時間範囲(スパン)で計算して、時系列グラフを作成しています。しかし、アラート用のモニターでは使用できないのが欠点です。 なぜなら、毎分計算されたスパンが時系列グラフに適用されるため、Autosmooth関数で適用された結果が一様でなくなる可能性があるためです。アラートの閾値あたりのデータがあるときに、アラートが発生したりしなかったりとノイズを発生させてしまうかもしれません。そのため、ダッシュボードにのみ使うことになります。以下のグラフのような人間の目では視認しづらいものを、平滑化してくれるため、監視の際に空目すること減りそうです 👀


Exponentially weighted moving average (指数加重移動平均 / 指数平滑移動平均)
Exponentially weighted moving average (ewma) は指数加重移動平均という日本語名称で、単純な移動平均に指数関数的な重み付けを付与した計算方法です。直近のデータの重みを最大とし、データが古くなるにつれて重みが指数関数的に減っていきます。そのため、単純な移動平均より、直近のデータの変動が反映されやすくなっているのが特徴です。 Datadogでは ewma_3, ewma_5, ewma_10, ewma_20 の種類があり、接尾辞の数字は重み付けの対象データ数を指しています。データ数が多いほど古いデータの変動が反映されるため、グラフが緩やかになります。以下のグラフでは、赤色が元データで、橙色が ewma_20 となっています。見てのとおりかなり平滑化されています(最大のデータ数を指定しているので当たり前ですが😅)。指数加重移動平均は、スパイクだけでなく、システム停止時などの急なデータの動きに対するグラフへの反映が鈍くなるため、アラート発生時に即時検知したい場合は向かないのではと思っています。

Median (中央値)
Medianは対象のデータ内の中央値をグラフに適用します。 Datadogでは median_3, median_5, median_7, median_9 の種類があり、ewma_n 同様、接尾辞は対象のデータ数を指しています。以下のグラフでは、水色が元データで、紫色が median_9 となっています。スパイクの頻度が低ければ平滑化されています。 しかし、連続したスパイク値(スパイクなのか怪しい 🤔)がある場合は、多少最大値が低いですがグラフに反映されています。中央値を適用したグラフは、指数加重移動平均よりデータの反応速度は優れていますが、先述したとおりスパイクが連続してしまうと閾値を超えてアラートとして処理される可能性があります。スパイクの頻度が低く、ノイズが発生しづらいのであれば中央値を適用したグラフにすると良いと思います。

まとめ
3つの平滑化関数を試しましたが、以下の理由から、私のサービスでは Median 関数を使用するつもりです。
- システム停止など緊急度が高いアラートに即時対応したい(指数加重移動平均では厳しい)
- アラートのノイズを減らしたいけど、今の段階ではすべてのノイズを取り除かなくてもいい(根本原因は年明けに解決するため)
当たり前ですが、それぞれの平滑化関数には善し悪しがあるので何をモニタリングしたいのかによって使い分けると良いです。本記事では平滑化関数を組み合わせることはしませんでしたが、関数の作用を理解して意図したとおりのグラフを得られるのであれば試してみて良いかなと思っています。ただ、初見の人には学習コストがかかるので、必要にならない限りやらないとは思います。
ここまで読んでくださりありがとうございました 🥰少しでも監視について役立ててもらえると幸いです 🙌
GoConference 2019 Autumn に参加してきたので学んだことをまとめました
はじめに
先日Go Conference 2019 Autumnに参加してきました。また、Goは半年前程から使い始めたので、Goのカンファレンスに参加したのは初めてでした。
セッションはテスト、エラーハンドリング、機械学習、ライブラリなどからエミュレータ、コンパイラなどの幅広いトピックがありました。 日本語のセッションだけでなく、英語のセッションも少数ありました。
本記事では自分が聴講したセッションのいくつかをまとめています。
API scenario testing tool with plugin package by Kenta Mori
GUIでのE2Eテストを楽にするためのツールを作成した話でした。
E2Eテストのペインを複雑性、再利用性、拡張性などの観点から解決しているのは印象的でした。 後半はLanguage serverで補完機能を実装するという内容ででなかなか骨が折れそうな話でした。
なぜ作ったのか
- PostmanでE2Eテストをすると色々不便な点がある
E2Eテストツールの内容
- JSONの複雑さに対処する
- YAML以外でも機能を拡張できるようにする
- Goの標準パッケージのpluginを利用して、YAML内からpluginを呼び出すことで機能の拡張を実現している
- すでに作成したシナリオを再利用する
- シナリオを組み込めるようになっており、変数として結果の値を保持できるため、他のステップで任意のシナリオの出力値を利用することができる
Accelerate Go development with Bazel by micnncim
GoでBazelというGoogleのビルドツールを試した話でした。
一部の会社ではBazelを採用していますが、go buildに戻した会社もあるということで、ユースケースで慎重に検討することを強調していました。なんのツールや仕組みでも銀の弾丸ではないので、ちゃんと考えて使いましょう。
Goのビルドのペイン
- マイクロサービスをMonorepoで運用する場合、数百のサービスを一度にビルドする必要がある
- KubernetesやIstioとかの巨大なコードベースの場合
go buildではビルド時間が長い
Bazelによって解決される事柄
- Go, Docker, protobufなどの複数のビルドをBazelでまとめてビルドできる
- サンドボックス環境でビルドを行うため、ビルドの再現性が高い
- 各人の開発環境や本番環境などの環境に依存しない
- ツールが豊富
- rules_xxx
- GoやDockerなどのBazelルールがあり、利用することでビルドが可能になる
- Gazelle
- Goのファイルの依存関係をみて、自動でビルドの設定を生成してくれる
- .bazelrc
- Bazelのオプションを記述でき手間が省ける
- Bazelisk
- Bazelのバージョン管理
- rules_xxx
個人的に参考になった記事
Goで"超高速"な経路探索エンジンをつくる by imoty
最短経路を求めるにあたって、地図のデータ化、ダイクストラ法などの基本的なところを中心に説明していました。
高速化をするためにGoのsliceやmapの実装構造から説明されており、Goビギナーの方でも理解しやすい内容だと思いました。
ベンチマークするとき
- pprofとbenchmarkオプションを使う
Sliceによる高速化
- sliceの基礎
- arrayは固定長、sliceは可変長でサイズを実行の途中で変更できる
- sliceは内部にarrayのポインタを持っている
- arrayのcapacityを超える場合、新しいarrayをアロケートし、コピーと切り替えを行う
- 高速化のポイント
- lengthやcapacityを指定してsliceを作成する
- メモリアロケートには時間がかかるため、予め必要なメモリ(capacity)を確保する
- lengthやcapacityを指定してsliceを作成する
Mapによる高速化
- mapの基礎
- Goにおけるmapはハッシュテーブルとなっている
- 内部ではBucketと呼ばれる配列があり、そこにキーと値のペアを保存している
- 高速化のポイント
- capacity hintを指定してmapの拡張を抑える
- ユースケースによってはsliceで代用することも考える
Mapの仕組みに関する記事
まとめ
GoConferenceでの個人的な学びをまとめると以下になります。
- Scenarigo使ってE2Eテストを楽に書く
- Bazelのビルドを試す
- SliceとMapのメモリ管理をする
- パフォーマンス計測する
Goを使い始めて間もないので、こういうカンファレンスに参加して基本的なことでも知らなかったことを知れることができたので良かったです。色々なコミュニティが活発になればエンジニア同士の交流も増え、知識の共有が組織間で行われるようになるため良いなと感じました!
TerraformでGCPのリソースの作成と変数から値を読み込む
はじめに
今回はTerraformというインフラ環境をコードで定義できるツールについてまとめました。
TerraformはHashCorp社が提供しており、Infrastructure as Code を実現するためのツールです。AWS, GCPなどのクラウド環境はもちろん、ここに記載されているプロバイダーはTerraformで構築することができます。
本記事ではTerrafromが提供しているチュートリアル(GCP)を参考にしています。
Terraformのインストール
まずはじめに、TerrafromはHomebrewでインストールできるので、以下のコマンドでインストールします。
> brew install terraform > terraform version Terraform v0.12.9
GCPのセッティング
今回はGoogle Cloud Platformを使用するため、以下の2つのセットアップを済ませておきましょう。
- GCPプロジェクトの作成
- Terraform用のサービスアカウントの作成
IAMと管理->サービスアカウント->サービスアカウントの作成へ移動- 適当なサービスアカウント名を入力
- 役割を
Project->編集者に設定する - キーを作成でキーのタイプをJSONに指定し作成する
Terraformはサービスアカウントを使ってGCPの各リソースにアクセスをおこないます。今回のチュートリアルでは、TerraformのサービスアカウントにProjectの編集者の権限を付与しています。
補足としてサービスアカウントの権限を絞りたい場合は、以下の権限を設定すれば本記事の操作は正常に処理できます。
- ComputeNetworkの管理者
- サービスアカウントの管理者
Providerの設定とGCPリソースの定義
TerraformでGCPリソースを操作するために、Googleのproviderの設定をする必要があります。providerの項目には認証用のファイルやプロジェクト名などの情報を記述します。
作成するファイル名はmain.tfとなっており、リソース作成の例としてVPCネットワークに関するコードも追加しています。
provider "google" { # サービスアカウントを作成したときにダウンロードしたJSONファイルのパスを指定します credentials = file("<NAME>.json") project = "<PROJECT_ID>" region = "asia-northeast1" zone = "asia-northeast1-a" } # VPCネットワークのリソースを作成する resource "google_compute_network" "vpc_network" { name = "terraform-network" }
Terraformの初期化
新しくTerraformを使う場合、terraform initで設定を初期化しproviderのpluginなどを追加する必要があります。
> terraform init Initializing the backend... Initializing provider plugins... * provider.google: version = "~> 2.17"
リソースの作成
次にterraform applyでリソースを作成します。作成時に変更前と後の差分が表示され適用するかどうか聞かれるのでyesを入力します。
リソース作成後にローカルのディレクトリをみると.terraform/terraform.tfstateというファイルが作られていることがわかります。これには、Terraformによって作成されたリソースの情報などが保存されています。本記事では紹介しませんが、チームで開発する際にインフラの状態を共有するためには、クラウドのストレージなどにアップロードして管理する必要があります。
> terraform apply An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create ...<中略> Enter a value: yes module.network.google_compute_network.network: Creating... ...<中略> Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
GCPコンソールでVPCネットワークが作成されているか確認しましょう。
terraform showでも設定が反映されているかを確認することができます。
> terraform show # google_compute_network.vpc_network: resource "google_compute_network" "network" { auto_create_subnetworks = false delete_default_routes_on_create = false id = "terraform-vpc-network" name = "terraform-vpc-network" project = "xxxxxx" routing_mode = "GLOBAL" self_link = "https://www.googleapis.com/compute/v1/projects/xxxxx/global/networks/terraform-vpc-network" }
変数を使用して値を読み込む
上記のやり方ではprojectやcredentialsを直にファイルに書き込んでいました。このファイルをGithubなどのバージョン管理システムにアップロードして管理するのはセキュリティ的によくありません。 したがって、秘匿したい変数を外部のファイルやコマンドライン引数から読み込むこととします。
変数を定義する
準備としてmain.tfに直接書き込んでいたパラメータで変数に置き換えたいものを variables.tf に記載します。
regionとzoneはデフォルト値を指定していますが、projectとcredentials_fileは後述する別ファイルまたはコマンドライン引数などから読み込むため空になっています。
variable "project" {} variable "credentials_file" {} variable "region" { default = "asia-northeast1" } variable "zone" { default = "asia-northeast1-b" }
main.tf ファイルで変数を使用する
次にmain.tfに直接書き込んでいたパラメータを変数に置き換えます。変数は var.<変数名> のように指定します。
provider "google" { credentials = file(var.credentials_file) project = var.project region = var.region zone = var.zone }
コマンドライン引数から読み込む
-varオプションで変数の組を引数に渡すことで読み込むことができます。
> terraform plan -var 'project=<PROJECT_ID>' -var 'credentials_file=<NAME>.json'
ファイルから読み込む
ファイルから変数を読み込むためにはterraform.tfvarsか接尾辞が.auto.tfvarsのファイルを作成します。作成後にterraform applyをすると自動で変数を読み込んでくれます。
project = "<PROJECT_ID>" credentials_file = "<NAME>.json"
terraform planやterrafom applyの実行時に-var-flieオプションを使用した場合は先述のファイル名である必要はありません。コマンドライン引数でsecret.tfvarsやdevelopment.txtなどを指定することで変数を読み込むことができます。
> terraform plan -var-file="secret.tfvars"
環境変数から読み込む
変数をマシンの環境変数から読み込みたい場合は、環境変数にTF_VAR_<変数名>を設定します。
今回の場合は以下の2つを追加すれば大丈夫です。
TF_VAR_project="<PROJECT_ID>"TF_VAR_credentials_file="<NAME>.json"
注意として、環境変数を使用する場合はstring型しか設定することができません。
Lists型やMaps型などは使用できないので、これらが必要な場合はファイルかコマンドライン引数で読み込むようにしてください。
リソースの削除
リソースを作成したままにしてしまうと課金されてしまう場合があるので削除しておきましょう。
作成したリソースを削除するためにはterraform destroyコマンドを使用します。削除するリソース内容と、削除するかを聞かれるのでyesと入力すれば環境を削除することができます。
> terraform destroy <削除するリソース内容> Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes
まとめ
今回は、Terraformでのリソース作成と変数をファイルなどから読み込む設定を行いました。
チュートリアルには、Google Compute Engineの作成や、チームでTerraformを使う際のやり方が記載されています。また、疑問に思ったことがあればTerraformのドキュメントに大体書いてあるのでサクサク試すことができました。
個人のプロジェクトでTerraformを使うかどうか迷っていまいしたが、環境の作成・変更・削除をコードで簡単にできるのは良いと感じました。実際に使ってみて知見があれば記事を書こうと思います!
参考文献
XP 祭り 2019で社内で開催したワークショップについてLTをしてきました
はじめに
先日、XP祭り2019でLT祭りに参加してきたので、LTの補足と簡単な参加レポートをまとめまておきます。LTでは「スプリントプランニングにおけるタスクの見積もりの質を向上させる」という目的で開催したワークショップについて紹介しました。
本記事では個人的にワークショップを設計する上で重要だと考えていることと、ワークショップの概要について説明します。
発表資料
ワークショップの設計で意識していること
私がワークショップを設計する時に重要だと思うポイントは以下の2つです。
- 参加者がワークショップ後にどのような状態になってほしいのか
- ワークショップで解決したい課題が解決または改善されるか

1. ワークショップ後の参加者の状態を決める
ワークショップはなにか目的があって開催されているはずなので、その目的を達成するためには参加者がどのような状態になっていないといけないのかを最初に決めます。 目標となる参加者の状態が決まれば、ワークショップのアイデアをひたすら出して効果的であるもの探していきます。
以下の図の通り、参加者が物事を理解し何かしらのアクションを起こすときにはレクチャーするだけは不十分ですが、ワークショップと組み合わせるとことで、自ら体験し気づきを得て、参加者の状態に変化を与えやすくなります。 気づきを与える方法としては以下のようなことが考えられますが、議論やフィードバックの内容などはファシリテーターや参加者に依存します。
- ワークショップ内で体験したことを考えてもらう or 議論する時間をとる
- ファシリテーターが参加者に直接フィードバックを与える

2. ワークショップで解決すべき課題を見失わないようにする
せっかく入念に設計をしたワークショップでも、当初のワークショップを企画するに至ったモチベーションを満たさなければ意味がありません。
自分が初めてワークショップを企画したときは、見様見真似であれもこれも良さそうなワークショップのコンテンツを盛り込んでいました。他のワークショップを参考にすることは良いですが、それらが何を達成するために設計されたものなのか意図を汲み取り、自分が解決したい課題に対して有効かを判断して使用する必要があります。
以上のようなことを防ぐために、ワークショップを設計するときは節目節目にワークショップで解決したい課題を解決できているのかを確認する必要があります。
開催したワークショップの内容
以上を踏まえて以下のようなワークショップを設計しました。ワークショップはシンプルで、目指す状態は「見積もり作業自体に違和感を持ってもらい今後の見積もり作業の改善につなげる」としています。内容は、グループを分けて見積もりをしてもらい、見積もり後に互いのグループで見積もり方法等を議論してもらいました。
今回は時間が短かったため、ワークショップ前にレクチャーの時間を十分に取ることができませんでした。参加者のスキルやコンテンツ内容にもよりますが、ワークショップの内容が参加者にとって簡単ではない場合はレクチャーの時間をとることをおすすめします。

参加したセッション・ワークショップについて
少ないですが参加したセッション・ワークショップについて簡単にまとめました。
リーダー、マネージャーが存在しない開発組織の作り方
自己組織化をテーマに、チーム内にリーダーやマネージャーをなくしていく過程を説明されていました。
個人的にはリーダやマネージャーの機能を各メンバーが持っていてチームとして成り立っているのであればOKな気もしました。
XP祭り2019 ぼくらはチームのかけら
お題は「来年のXP祭りを盛り上げる」でメンバー4人のチームをいくつか作り、チーム内で様々なチームビルディングの手法を試していくというものでした。
互いの価値観を説明し合う方法として、「ムービングモチベーターズ」というManagement 3.0 のプラクティスが入っており、初対面でしたがチームメンバーとの距離が縮まりとてもよかったです。自分のチームでもやれる機会があれば提案してみようと思いました。
ワークショップを円滑にすすめるための事前説明がスムーズで進行がとても上手でワークショップを全力で楽しむことができました!
まとめ
XP祭りは初参加でしたがワークショップを中心に楽しむことができました。
今回はLT枠でワークショップの開催事例とともに簡単なノウハウをお伝えしましたが、来年はトーク枠として出ることができればと思います!
Goのエラーハンドリングの基本的な考え方
はじめに
アプリケーションの開発においてエラーハンドリングの設計は重要です。エラーハンドリングの設計を軽視すると、エラー発生時に原因が明確にわからないことや、エンドユーザーに対して不親切なエラーメッセージを返すことになってしまってもおかしくはありません。
本記事ではGoのエラーハンドリングの基本的な考え方について紹介します。
エラーについて
エラーはプログラムが異常な処理をした場合に発生するもので、Ben Johnson氏の記事によるとエラーは以下の2つに分けることができます。
- well-defined error(明確なエラー)
- ハンドリングできているエラーで、アプリケーション内で予測できているエラー
- undefined error(未定義のエラー)
- panicなどアプリケーションで予測できていないエラー
エラーはただ返せば良いわけではない
エラーは処理に失敗したときにerrをただ表示するだけではエラーハンドリングを十分に行えているとは言えません。エラーを扱うシーンによって、エラーに含める情報やエラーハンドリングを工夫する必要があります。エラーの利用シーンは主に以下の3つに分けられ、それぞれのシーンでエラーの扱い方は異なります。
- アプリケーション内でエラーを扱うとき
- エラーにアプリケーション固有のエラーコードを加えることで、エラーを識別しエラーハンドリング可能な状態にする
- エンドユーザーがエラーをみるとき
- エラーに人間が読んでわかるメッセージを含めて、ユーザーがエラーメッセージを見て行動を取れる状態にする
- オペレーターがエラーをみて障害対応などをするとき
- エラーにオペレーションの情報を含めてスタックしておくことで、システムの運用者がエラーの発生原因を特定しやすくする
サンプル
実際にどのようにエラーを実装していけばよいのかを擬似コードをもとに説明していきます。
エラーの定義例
先ほどのエラーの利用シーンに対応するためには、エラーに以下の情報を含める必要があります。
- アプリケーション固有のエラーコード
- エンドユーザー向けに表示するメッセージ
- 発生源のエラーやラップされたエラーを格納するエラー
コードにすると以下のようになります。ApplicationErrorはエラーコードの他に、Errorメソッドを持っておりerrorインターフェースを満たすようになっています。
type ApplicationError struct { // Code is ApplicationErrorCode Code string // Message is to show enduser Message string // Err is nested error Err error } // Error is implementation for error interface func (e *ApplicationError) Error() string { errStr := "" if e.Err != nil { errStr := fmt.Sprintf("%s", e.Err.Error()) } return fmt.Sprintf("code=%s, err=%s, msg=%s", e.Code, errStr, e.Message) }
UserService.FindByIDのエラー変換の実装例
今回は仮の実装としてUserService.FindByIDから返されるエラーを内部のエラーに変換してみます。まずは、以下のようなアプリケーション固有の内部のエラーコードを定義します。内部のエラーコードは、外部サービスやライブラリのエラーコードを、アプリケーション固有のエラーコードとして扱うために利用されます。アプリケーションでは内部のエラーコードを利用してエラーハンドリングを行います。
// ApplicationErrorCode const( InternalServerErrorCode = "InternalServerError" NotFoundErrorCode = "NotFoundError" InvalidArgumentErrorCode = "InvalidArgumentError" )
以下のコードではUserService.client.Getのエラーを場合に応じて内部のエラーコードに変換しています。エラーが有る場合はgRPCのステータスコードがあるかないかをチェックして、内部のエラーコードであるInternalServerErrorCodeやNotFoundErrorCodeに変換しています。NotFoundErrorCodeの場合はエンドユーザー向けに人間が理解可能なメッセージを付与しています。InternalServerErrorの場合はエラーをpkg/errorsなどでラップして詳細な情報を加えることで、システムの運用者がエラーの原因を追いやすくなるようにしています。
func (s *UserService) FindByID(id string) (*User, error) { res, err := s.client.Get(id) if err != nil { // err to gRPC status status, ok := status.FromError(err) if !ok { return nil, &apperr.ApplicationError{Code: apperr.InternalServerErrorCode, Err: errors.Wrapf(err, "grpc connection is failed")} } // external error to internal error switch status.Code() { case codes.NotFound: // respond err message to enduser return nil, &apperr.ApplicationError{Code: apperr.NotFoundErrorCode, Message: "ユーザーが見つかりませんでした", Err: err} case default: // wrap original error and add detail information return nil, &apperr.ApplicationError{Code: apperr.InternalServerErrorCode, Err: errors.Wrapf(err, "UserService.Get() responds error: id=%s", id)} } } return &User{ ID: res.userID, Name: res.name, }, nil }
固有エラーからgRPCステータスコードへのエラーハンドリング例
この実装例では内部のエラーコードをgRPCのステータスーコードに変換しています。err.(apperr.ApplicationError)により、定義したアプリケーション内部のエラーコードのみでエラーハンドリングを行います。外部のエラーを内部のエラーに変換しておくことで、最終的にエラーハンドリングする際に懸念事項をぐっと減らすことができます。
func grpcStatus(err error) codes.Code { if e, ok := err.(apperr.ApplicationError); ok { switch e.Code { case domainerr.InternalServerErrCode: return codes.Internal case apperr.NotFoundErrorCode: return codes.NotFound case apperr.InvalidArgumentErrorCode: return codes.InvalidArgument } } return codes.Internal }
まとめ
今回はエラーハンドリングについて例を踏まえてまとめました。これは基本的なエラーの設計方針にとどまっているため、実際の実装はシステムによって様々です。またエラーについて記事を書くことがあれば、実際のアプリケーションでエラーハンドリング設計から実装までを紹介できればと思います。
参考文献
gRPC/GoのServerをGKEにデプロイする
はじめに
今回はGoogle Kubernetes Engine(GKE)を利用してgRPC通信の動作検証をしました。
本記事ではGoを使用したgRPC通信の実装例と、GKEへのデプロイ手順を記載しています。
構成図は以下のようになります。LoadBalancer(LB)でgRPCリクエストを受け付けてPodにリクエストをしています。Pod内では BookService が UserService にgRPCリクエストをして、得られた情報をもとにレスポンスを返しています。

- はじめに
- 検証に使用したプログラム
- user_service/main.go の実装
- book_service/main.go の実装
- Dockerイメージの作成とGoogle Cloud Registry(GCR)への登録
- サーバーを動かすためのGKEクラスタの作成
- ローカルからGKEクラスタにgRPCリクエストをする
- まとめ
- 参考文献
検証に使用したプログラム
今回使用したプログラムは、前回の記事で作成した y-zumi/grpc-go に機能を追加したものです。
パッケージ構成は以下のようになっており、 book_service と user_service の2つのサービスと、それぞれに対応するDockerfileとprotoファイルがあります。 deployment.yaml は各サービスをGKEへデプロイする際に使用します。
├── book_service │ └── main.go ├── user_service │ └── main.go ├── docker │ ├── book │ │ └── Dockerfile │ └── user │ └── Dockerfile ├── proto │ ├── book │ │ ├── book.pb.go │ │ └── book.proto │ └── user │ ├── user.pb.go │ └── user.proto └── deployment.yaml
user_service/main.go の実装
UserServiceの実装は以下のようになります。
- UserServiceの定義
- FindByIDメソッドの定義
- main関数の定義
- gRPC Serverの起動
- gRPC ServerにUserServiceを登録する
UserServiceの定義
proto/user/user.proto をもとにUserServiceの構造体とメソッドを定義しています。UserServiceにはFindByIDというRemoteProcedureCall(RPC)を定義しています。FindByIDは「UserのidをもとにUserの情報を返す」RPCです。
service Users { // Find user by user id rpc FindByID (FindByIDRequest) returns (FindByIDResponse) {} } // Find user information message FindByIDRequest { string id = 1; } // Return information of found user message FindByIDResponse { User user = 1; } // A User resource message User { // user's id string id = 1; // user's nickname string name = 2; }
main関数の定義
main関数の中ではgRPC Serverの起動と、UserServiceをgRPC Serverに登録する処理を実装しています。
func main() { // Start listening port lis, err := net.Listen("tcp", ":50001") if err != nil { log.Fatalf("failed to listen: %v", err) } // Register UsersServer to gRPC Server s := grpc.NewServer() user.RegisterUsersServer(s, &UserService{}) // Add grpc.reflection.v1alpha.ServerReflection reflection.Register(s) // Start server if err := s.Serve(lis); err != nil { log.Fatalf("failed to serve: %v", err) } }
book_service/main.go の実装
BookServiceの実装はUserServiceと同様に以下のようになります。
- BookServiceの定義
- FindLendingBookByIDメソッドの定義
- main関数の定義
- gRPC Serverの起動
- gRPC ServerにBookServiceを登録する
BookServiceの定義
proto/book/book.proto をもとにBookServiceの構造体とメソッドを定義しています。BookServiceにはFindLendingBookByIDという「任意の本の貸出情報を取得し返す」RPCを定義しています。本の貸出情報はFindLendingBookByIDResponseに定義されており、BookとUserの情報が含まれています。
service Books { rpc FindLendingBookByID (FindLendingBookByIDRequest) returns (FindLendingBookByIDResponse); } message FindLendingBookByIDResponse { Book book = 1; user.User borrower = 2; } message Book { string id = 1; string title = 2; string status = 3; }
FindLendingBookByIDResponseにはUserの情報が含まれていますが、BookServiceはUserの情報を持っていないためUserServiceに問い合わせる必要があります。そのため、BookServiceはFindLendingBookByID内で、UserServiceへgRPCリクエストをしてUserの情報を取得しています。
type BookService struct { client user.UsersClient } func (s *BookService) FindLendingBookByID(ctx context.Context, req *book.FindLendingBookByIDRequest) (*book.FindLendingBookByIDResponse, error) { // request UserService findByIDRequest := user.FindByIDRequest{ Id: faker.UUIDDigit(), } borrower, err := s.client.FindByID(ctx, &findByIDRequest) if err != nil { return nil, errors.New("user is not found error") } return &book.FindLendingBookByIDResponse{ Book: &book.Book{ Id: req.Id, Title: faker.Word(), Status: BookStatusLending, }, Borrower: borrower.User, }, nil }
main関数の定義
gRPC Serverの起動は同じ実装ですが、BookServiceはUserServiceにアクセスする必要があるため、UserServiceにアクセスするためのUserClientの実装もmain関数内で行っています。
func main() { // Start listening port // 省略 // Register BookService to gRPC Server s := grpc.NewServer() bookService, err := createBookService() if err != nil { log.Fatalf("did not create book service: %v", err) } book.RegisterBooksServer(s, bookService) // Start server // 省略 } func createBookService() (*BookService, error) { cli, err := newUserClient() if err != nil { return nil, errors.Wrap(err, "did not create user client") } return NewBookService(cli), nil } func NewBookService(client user.UsersClient) *BookService { return &BookService{ client: client, } } func newUserClient() (user.UsersClient, error) { conn, err := grpc.Dial("localhost:50001", grpc.WithInsecure()) if err != nil { return nil, errors.Wrap(err, "did not connect localhost:5001") } return user.NewUsersClient(conn), nil }
Dockerイメージの作成とGoogle Cloud Registry(GCR)への登録
docker/ディレクトリ配下にUserServiceとBookServiceのDockerfileがあります。ファイルの中身は以下のようになっています
FROM golang:1.13.0 AS builder WORKDIR /go/src/github.com/y-zumi/grpc-go COPY . . RUN make build-user FROM alpine:latest RUN apk add --no-cache ca-certificates COPY --from=builder /go/src/github.com/y-zumi/grpc-go/bin/user /usr/local/bin ENTRYPOINT ["/usr/local/bin/user"]
imageの作成は以下のコマンドで行います。今回はDockerイメージをGCRに登録するためイメージの名前をgcr.io/[YOUR_PROJECT_ID]/user-service:v1.0のようにする必要があります。
[YOUR_PROJCET_ID]にはご自身のGoogle Cloud Platform ConsoleのプロジェクトIDを記載してください。
> docker build --tag gcr.io/[YOUR_PROJECT_ID]/user-service:v1.0 -f docker/user/Dockerfile . Sending build context to Docker daemon ... > docker build --tag gcr.io/[YOUR_PROJECT_ID]/book-service:v1.0 -f docker/book/Dockerfile . Sending build context to Docker daemon ...
GCRへのDockerイメージの登録は以下のコマンドで行います。
登録後はgcloud container image listで無事に登録できているか確かめることができます。
> gcloud auth configure-docker > docker push gcr.io/[YOUR_PROJECT_ID]/user-service:v1.0 The push refers to repository [gcr.io/[YOUR_PROJECT_ID]/user-service] ... > docker push gcr.io/[YOUR_PROJECT_ID]/book-service:v1.0 The push refers to repository [gcr.io/[YOUR_PROJECT_ID]/book-service] ... > gcloud container images list NAME gcr.io/[YOUR_PROJECT_ID]/book-service gcr.io/[YOUR_PROJECT_ID]/user-service
サーバーを動かすためのGKEクラスタの作成
次はGKEクラスタを作成し、UserServiceとBookServiceをGKEクラスタにデプロイします。
クラスタの作成は以下のコマンドで行います。
> gcloud container clusters create grpc-go-cluster --zone asia-northeast1 --num-node 1 > gcloud container clusters list NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS grpc-go-cluster asia-northeast1 1.13.7-gke.8 35.243.122.104 n1-standard-1 1.13.7-gke.8 3 RUNNING
DeploymentとServiceはdeployment.yamlにまとめて実装しています。
Deploymentをみると、1つのPodでuser-serviceとbook-serviceの2つのコンテナが起動するようになっています。Serviceでは、ポート80でアクセスを受け付けて、ポート50011(book-service)に転送しています。
apiVersion: apps/v1 kind: Deployment metadata: name: grpc-go-deployment labels: app: grpc-go spec: replicas: 3 selector: matchLabels: app: grpc-go template: metadata: labels: app: grpc-go spec: containers: - name: user-service image: gcr.io/kouzoh-p-y-zumi/user-service:v1.0 ports: - containerPort: 50001 - name: book-service image: gcr.io/kouzoh-p-y-zumi/book-service:v1.0 ports: - containerPort: 50011 --- apiVersion: v1 kind: Service metadata: name: grpc-go-service spec: type: LoadBalancer selector: app: grpc-go ports: - port: 80 targetPort: 50011 protocol: TCP
以下のコマンドでGKEクラスタにDeploymentなどを作成し、BookServiceとUserServiceを起動させます。
実際にPodが動いていることが確認できれば大丈夫です。
> kubectl apply -f deployment.yaml deployment.apps/grpc-go-deployment created service/grpc-go-service created > kubectl get pods NAME READY STATUS RESTARTS AGE grpc-go-deployment-57bbc76bd4-js9xf 2/2 Running 0 46s grpc-go-deployment-57bbc76bd4-nlkkg 2/2 Running 0 46s grpc-go-deployment-57bbc76bd4-tw84j 2/2 Running 0 46s
ローカルからGKEクラスタにgRPCリクエストをする
grpc-go-serviceのEXTERNAL_IPにgrpcurlを使ってgRPCリクエストをします。
レスポンスが返ってきていることが確認できたらgRPC通信が成功しています。
> kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grpc-go-service LoadBalancer 10.47.242.103 34.84.72.59 80:32415/TCP 4h48m kubernetes ClusterIP 10.47.240.1 <none> 443/TCP 5h45m > grpcurl ls -k 34.84.72.59:80 book.Books grpc.reflection.v1alpha.ServerReflection > echo '{"id": "12345"}' | grpcurl -k call 34.84.72.59:80 book.Books.FindLendingBookByID | jq . { "book": { "id": "12345", "title": "eligendi", "status": "Lending" }, "borrower": { "id": "80546886febf4166b236df1214afa559", "name": "Prof. Yasmeen Casper" } }
まとめ
今回はGKEクラスタにgRPC Serverをデプロイして動作確認を行いました。Kubernetesは少ししか触れていませんが、様々な設定をすることができるので、今後の記事で試してみようと思います。